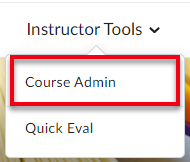
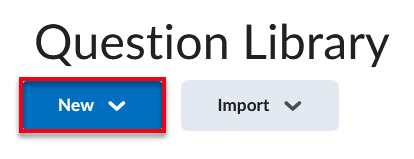
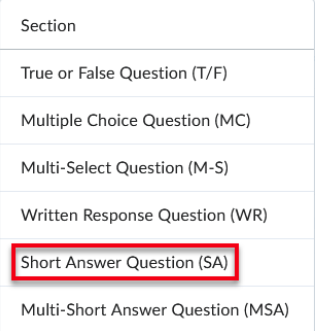
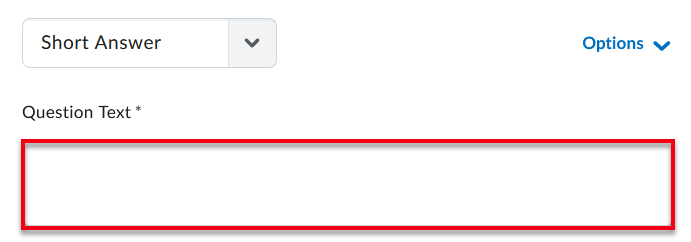
Character
| Description
| Example
|
\
| Marks the next character as a special character, a literal, a back-reference, or an octal escape.
| The sequence \\ matches \ and \( matches (
n matches the character n
\n matches a new-line character
|
^
| Matches the position at the beginning of the input string. If the RegExp object’s Multi-line property is set, ^ also matches the position following '\n' or '\r'.
| ^cat matches strings that begin with cat
|
$
| Matches the position at the end of the input string. If the RegExp object’s Multi-line property is set, $ also matches the position preceding '\n' or '\r'.
| cat$ matches any string that ends with cat
|
*
| Matches the preceding character or sub-expression zero or more times.
* equals {0,}
| be* matches b or be or beeeeeeeeee
zo* matches z and zoo
|
+
| Matches the preceding character or sub-expression one or more times.
+ equals {1,}.
| be+ matches be or bee but not b
|
?
| Matches the preceding character or sub-expression zero or one time.
? equals {0,1}
| abc? matches ab or abc
colou?r matches color or colour but not colouur
do(es)? matches the do in do or does
|
| When this character immediately follows any of the other quantifiers (*, +, ?, {n}, {n,}, {n,m}), the matching pattern is non-greedy. A non-greedy pattern matches as little of the searched string as possible, whereas the default greedy pattern matches as much of the searched string as possible.
| In the string oooo, o+? matches a single o, while o+ matches all os
|
()
| Parentheses create a sub-string or item that you can apply meta-characters to.
| a(bee)?t matches at or abeet but not abet
|
{n,}
| n is a non-negative integer. Matches exactly n times.
| [0-9]{3,} matches any three digits
o{2,} does not match the o in Bob, but matches the two os in food
b{4,} matches bbbb
|
{n}
| n is a non-negative integer. Matches at least n times.
| [0-9]{3} matches any three or more digits
o{2} does not match the o in Bob and matches all the os in foooood
o{1} is equivalent to o+
o{0} is equivalent to o*
|
{n,m}
| m and n are non-negative integers, where n <= m. Matches at least n and at most m times.
Note: You cannot put a space between the comma and the numbers.
| [0-9]{3,5} matches any three, four, or five digits
o{1,3} matches the first three os in fooooood
o{0,1} is equivalent to o?
c{2, 4} matches cc, ccc, cccc
|
.
| Matches any single character except "\n".
To match any character including the '\n', use a pattern such as '[\s\S]'.
| cat. matches catT and cat2 but not catty
|
(?!)
| Makes the remainder of the regular expression case insensitive.
| ca(?i)se matches caSE but not CASE
|
(pattern)
| Matches pattern and captures the match. The captured match can be retrieved from the resulting Matches collection, using the SubMatches collection in VBScript or the $0$9 properties in JScript.
To match parentheses characters ( ), use '\(' or '\)'.
| (jam){2} matches jamjam
First group matches jam
|
(?:pattern)
| Matches pattern but does not capture the match, that is, it is a non-capturing match that is not stored for possible later use.
This is useful for combining parts of a pattern with the "or" character (|).
| industr(?: y|ies) is a more economical expression than industry|industries
|
(?=pattern)
| Positive lookahead matches the search string at any point where a string matching pattern begins. This is a non-capturing match, that is, the match is not captured for possible later use.
Lookaheads do not consume characters: after a match occurs, the search for the next match begins immediately following the last match, not after the characters that comprised the lookahead.
| Windows (?=95|98|NT|2000) matches Windows in Windows 2000 but not Windows in Windows 3.1
|
(?!pattern)
| Negative lookahead matches the search string at any point where a string not matching pattern begins. This is a non-capturing match, that is, the match is not captured for possible later use.
Lookaheads do not consume characters, that is, after a match occurs, the search for the next match begins immediately following the last match, not after the characters that comprised the lookahead.
| Windows (?!95|98|NT|2000) matches Windows in Windows 3.1 but does not match Windows in Windows 2000
|
x|y
| Matches x or y.
| July (first|1st|1) matches July 1st but does not match July 2
z|food matches z or food
( z|f)ood matches zood or food
|
[xyz]
| A character set. Matches any one of the enclosed characters.
| gr[ae]y matches gray or grey
[abc] matches the a in plain
|
[^xyz]
| A negative character set. Matches any character not enclosed.
| 1[^02] matches 13 or 11 but not 10 or 12
[^abc] matches the p in plain
|
[a-z]
| A range of characters. Matches any character in the specified range.
| [1-9] matches any single digit except 0
[a-z] matches any lowercase alphabetic character in the range a through z
|
[^a-z]
| A negative range of characters.
Matches any character not in the specified range.
| [^a-z] matches any character not in the range a through z
|
\b
| Matches a word boundary: the position between a word and a space.
| er\b matches the er in never but not the er in verb
|
\B
| Matches a non-word boundary.
| er\B matches the er in verb but not the er in never
|
\cx
| Matches the control character indicated by x.
The value of x must be in the range of A-Z or a-z.
If not, c is assumed to be a literal 'c' character.
| \cM matches a Control-M or carriage return character
|
\d
| Matches a digit character.
Equivalent to [0-9]
|
|
\D
| Matches a non-digit character
Equivalent to [^0-9]
|
|
\f
| Matches a form-feed character.
Equivalent to \x0c and \cL
|
|
\n
| Matches a new-line character.
Equivalent to \x0a and \cJ
|
|
\r
| Matches a carriage return character.
Equivalent to \x0d and \cM
|
|
\s
| Matches any white space character including space, tab, form-feed, etc.
Equivalent to [\f\n\r\t\v]
| Can be combined in the same way as [\d\s], which matches a character that is a digit or whitespace
|
\S
| Matches any non-white space character.
Equivalent to [^\f\n\r\t\v]
|
|
\t
| Matches a tab character.
Equivalent to \x09 and \cI
|
|
\v
| Matches a vertical tab character.
Equivalent to \x0b and \cK
|
|
\w
| Matches any word character including underscore.
Equivalent to '[A-Za-z0-9_]'
|
|
\W
| Matches any non-word character.
Equivalent to '[^A-Za-z0-9_]'
You should only use \D, \W and \S outside character classes.
|
|
\Z
| Matches the end of the string the regular expression is applied to. Matches a position, but never matches before line breaks.
| .\Z matches k in jol\hok
|
\xn
| Matches n, where n is a hexadecimal escape value.
Hexadecimal escape values must be exactly two digits long.
Allows ASCII codes to be used in regular expressions.
| \x41 matches A
\x041 is equivalent to \x04 and 1
|
\num
| Matches num, where num is a positive integer.
A reference back to captured matches.
| (.)\1 matches two consecutive identical characters
|
\n
| Identifies either an octal escape value or a back-reference.
If \n is preceded by at least n captured sub-expressions, n is a back-reference.
Otherwise, n is an octal escape value if n is an octal digit (0-7).
| \11 and \011 both match a tab character
\0011 is the equivalent of 1
|
\nm
| Identifies either an octal escape value or a back-reference.
If \nm is preceded by at least nm captured sub-expressions, nm is a back-reference.
If \nm is preceded by at least n captures, n is a back-reference followed by literal m.
If neither of the preceding conditions exists, \nm matches octal escape value nm when n and m are octal digits (0-7).
|
|
\nml
| Matches octal escape value nml when n is an octal digit (0-3) and m and l are octal digits (0-7).
|
|
\un
| Matches n, where n is a Unicode character expressed as four hexadecimal digits.
| For example, \u00A9 matches the copyright symbol (©)
|